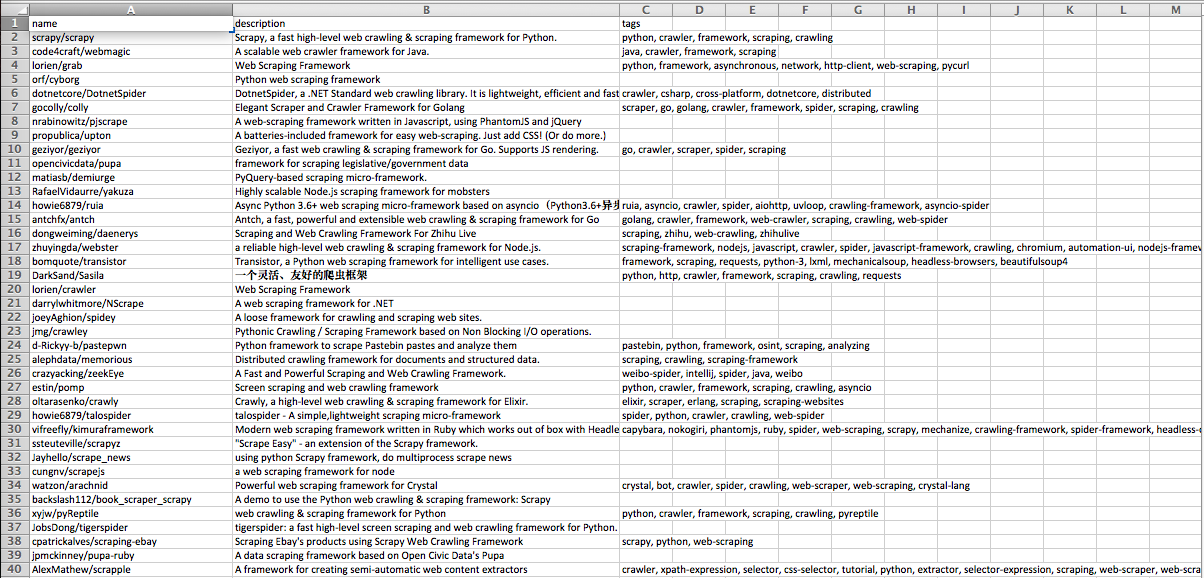
Example scraping script¶
A complete scraping script to scrape Github search result pages. View the source file.
#encoding: utf8
import sys
import logging
from collections import OrderedDict
from scrapex import Scraper
from scrapex import common
logging.basicConfig(
stream=sys.stdout,
level=logging.INFO,
format='%(levelname)s %(message)s')
logger = logging.getLogger(__name__)
#create the scraper object
#enable the cache system so that we can re-run the scrape without re-downloading the html files
s = Scraper(use_cache=True, greeting=True)
def scrape():
"""
- scrape repos from this search (first 5 result pages):
https://github.com/search?q=scraping%20framework
- results are save into an excel file: results.xlsx
"""
url = 'https://github.com/search?q=scraping%20framework'
page = 0
while True:
page += 1
doc = s.load(url)
if page==1:
logger.info(doc.extract("//h3[contains(text(),'results')]").strip())
listings = doc.query("//ul[@class='repo-list']/li")
logger.info('page# %s >> %s listings', page, len(listings))
for listing in listings:
item = OrderedDict()
item['name'] = listing.extract(".//div[contains(@class,'text-normal')]/a")
item['description'] = listing.extract(".//div[@class='mt-n1']/p").rr('\s+',' ').strip()
item['tags'] = listing.query(".//a[contains(@class,'topic-tag')]").join(', ')
#save this item to excel file
s.save(item,'results.xlsx')
#find the url of the next result page
url = doc.x("//a[.='Next']/@href")
if url:
logger.info('next page url: %s', url)
else:
logger.info('last page reached')
if page == 5:
break
if __name__ == '__main__':
scrape()
Output screen:
CungMac:demo cung$ python example-script.py
scrape started
INFO 443 repository results
INFO page# 1 >> 10 listings
INFO next page url: https://github.com/search?p=2&q=scraping+framework&type=Repositories
INFO page# 2 >> 10 listings
INFO next page url: https://github.com/search?p=3&q=scraping+framework&type=Repositories
INFO page# 3 >> 10 listings
INFO next page url: https://github.com/search?p=4&q=scraping+framework&type=Repositories
INFO page# 4 >> 10 listings
INFO next page url: https://github.com/search?p=5&q=scraping+framework&type=Repositories
INFO page# 5 >> 10 listings
INFO next page url: https://github.com/search?p=6&q=scraping+framework&type=Repositories
scrape finished
The results file screenshot: